
O JPA é um framework utilizado na camada de persistência (ver Figura 01) para o desenvolvedor ter uma maior produtividade, com impacto principal num modo para controlarmos a persistência dentro de Java. Pela primeira vez, nós, desenvolvedores temos um modo "padrão" para mapear nossos objetos para os do Banco de Dados. Persistência é uma abstração de alto-nível sobre JDBC.
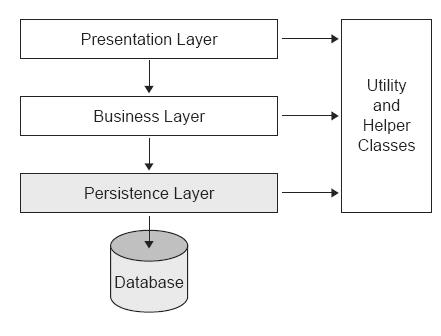
Figura 01.
O Java Persistence API - JPA define um caminho para mapear Plain Old Java Objects POJOs para um banco de dados, estes POJOs são chamados de beans de entidade. Beans de Entidades são como qualquer outra classe Java, exceto que este tem que ser mapeado usando Java Persistence Metadata, para um banco de dados.
A nova Java Persistence Specitication define mapeamento entre o objeto Java e o banco de dados utilizando ORM, de forma que Beans de entidade podem ser portados facilmente entre um fabricante a outro.
O que é ORM?
Em resumo, mapeamento objeto/relacional é automatizado (e transparente) persistência de objetos em aplicações Java para tabelas em um banco de dados relacional, usando metadata que descreve o mapeamento entre os objetos e o banco de dados.
Para uma simples comparação, vamos dá uma olhada em dois códigos para demostrar como JPA é muitissímo utíl para uma aplicação Java. Primeiro irei criar um exemplo utilizando JDBC, e um outro utilizando JPA.
Segue a estrutura da tabela:
CREATE TABLE bug (
id_bug int(11) NOT NULL auto_increment,
titulo varchar(60) NOT NULL,
data date default NULL,
texto text NOT NULL,
PRIMARY KEY (id_bug)
);
Na utilização do JPA é necessário o os dois jar’s do TopLink:
toplink-essentials.jar e o toplink-essentials-agent.jar
Link para download:
http://www.oracle.com/technology/products/ias/toplink/jpa/download.html
Adicione esses dois jar’s no ClassPath do seu projeto, e adicione também o Driver JDBC do seu Banco ;-)
Vamos dá uma olhada no código utilizando JDBC.
Listagem 01. JDBCCode.java.
package jdbc;
import java.sql.*;
/**
*
* @author adm
*/
public class JDBCCode {
private static Connection con = null;
/** Creates a new instance of JDBCCode */
public JDBCCode() {
}
public static Connection open(){
String user = "root";
String pass = "123456";
String url = "jdbc:mysql://localhost/bug";
try{
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection(url,user,pass);
}catch( Exception e ){
e.printStackTrace();
}
return con;
}
public static void main( String args[] ) throws Exception{
String sql = "SELECT * FROM bug";
con = open();
try {
Statement st= con.createStatement();
ResultSet rs= st.executeQuery(sql);
while( rs.next() ){
System.out.println("Titulo: "+ rs.getString("titulo"));
}
} catch (SQLException ex) {
ex.printStackTrace();
}finally{
con.close();
}
}
}
Uma classe bem simples, que lista os titulos dos bugs, mas são muitas linhas para escrever.... agora vamos dá uma olhada no código para selecionar um determinado registro utilizando JPA.
Listagem 02. Sniped code.
public Object findByPk( int pKey ) {
EntityManager em = getEntityManager();
return em.find(Bug.class, pKey);
}
Pronto!!! Mas isso é só para você comparar como nós ganhamos produtividade na camada de persistência, e portanto tendo mais tempo para os objetos da lógica negócio.
Agora vamos ao exemplo real, segue o objeto Bug ou o Entity Bean Bug:
Nossa classe deve implementar Serializable e ter um campo ID. Os arrobas em cima dos atributos, são as anotações para mapear o seu objeto para a tabela Bug.
A Figura 02 mostra o mapeamento entre o objeto Java e a tabela no banco de dados.
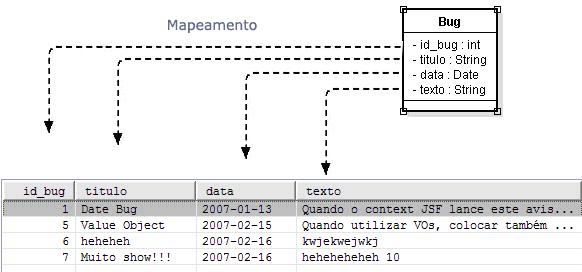
Figura 02.
Listagem 03. Bug.java.
/*
* Bug.java
*
*/
package exemplo;
import javax.persistence.*;
/**
*
* @author Wendell Miranda
*/
@Entity
@Table(name="bug")
public class Bug implements java.io.Serializable {
private Integer id_bug;
private String titulo;
private java.util.Date data;
private String texto;
/** Creates a new instance of Bug */
public Bug() {
}
/*
A notação @GeneratedValue(strategy=GenerationType.SEQUENCE) informa que o id será gerado automaticamente pelo DB.
*/
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE)
@Column(name="id_bug")
public Integer getId_bug() {
return id_bug;
}
public void setId_bug(Integer id_bug) {
this.id_bug = id_bug;
}
@Column(name="titulo")
public String getTitulo() {
return titulo;
}
public void setTitulo(String titulo) {
this.titulo = titulo;
}
@Temporal(TemporalType.DATE)
@Column(name="data")
public java.util.Date getData() {
return data;
}
public void setData(java.util.Date data) {
this.data = data;
}
@Column(name="texto")
public String getTexto() {
return texto;
}
public void setTexto(String texto) {
this.texto = texto;
}
@Override
public String toString(){
return "ID: "+this.id_bug;
}
}
Conclusões
fonte:http://www.devmedia.com.br/articles/viewcomp.asp?comp=4590




Nenhum comentário:
Postar um comentário